Optimize ast-grep to get 10X faster
In this post I will discuss how to optimize the Rust CLI tool ast-grep to become 10 times faster.
Rust itself usually runs fast enough, but it is not a silver bullet to all performance issues.
In this case, I did not pay enough attention to runtime details or opted for naive implementation for a quick prototype. And these inadvertent mistakes and deliberate slacking off became ast-grep's bottleneck.
Context
ast-grep is my hobby project to help you search and rewrite code using abstract syntax tree.
Conceptually, ast-grep takes a piece of pattern code (think it like a regular expression but for AST), matches the pattern against your codebase and gives a list of matched AST nodes back to you. See the playground for a live demo.
I designed ast-grep's architecture with performance in mind. Here are a few performance related highlights:
- it is written in Rust, a native language compiled to machine code.
- it uses the venerable C library tree-sitter to parse code, which is the same library powering GitHub's codesearch.
- its command line interface is built upon ignore, the same crates used by the blazing fast ripgrep.
Okay, enough self-promotion BS. If it is designed to be fast, how comes this blog? Let's dive into the performance bottleneck I found in my bad code.
Spoiler. It's my bad to write slow Rust.
Profiling
The first thing to optimize a program is to profile it. I am lazy this time and just uses the flamegraph tool.
Installing it is simple.
cargo install flamegraphThen run it against ast-grep! No other setup is needed, compared to other profiling tools!
This time I'm using an ast-grep port of es-lint against TypeScript's src folder.
This is the profiling command I used.
sudo flamegraph -- ast-grep scan -c eslint/sgconfig.yml TypeScript/src --json > /dev/nullThe flamegraph looks like this.
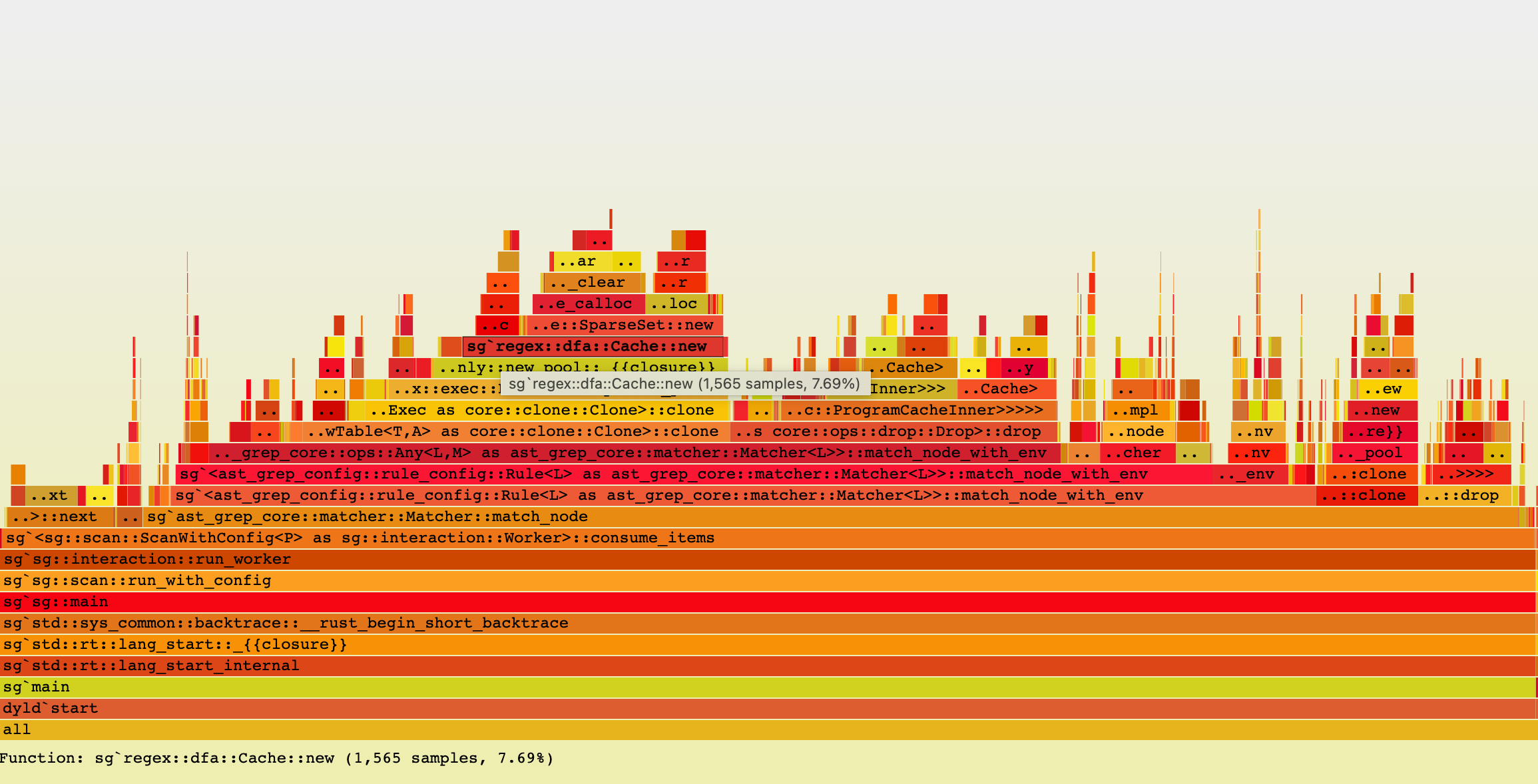
Optimizing the program is a matter of finding the hotspots in the flamegraph and fix them.
For a more intuitive feeling about performance, I used the old command time to measure the wall time to run the command. The result is not good.
time ast-grep scan -c eslint/sgconfig.yml TypeScript/src
17.63s user, 0.46s system, 167% cpu, 10.823 totalThe time before user is the actual CPU time spent on my program. The time before total represents the wall time. The ratio between them is the CPU utilization. In this case, it is 167%. It means my program is not fully utilizing the CPU.
It only runs six rules against the codebase and it costs about 10 whole seconds!
In contrast, running one ast-grep pattern agasint the TypeScript source only costs 0.5 second and the CPU utilization is decent.
time ast-grep run -p '$A && $A()' TypeScript/src --json > /dev/null
1.96s user, 0.11s system, 329% cpu, 0.628 totalExpensive Regex Cloning
The first thing I noticed is that the regex::Regex type is cloned a lot. I do know it is expensive to compile a regex, but I did not expect cloning one will be the bottleneck. Much to my limited understanding, dropping Regex is also expensive!
Fortunately the fix is simple: I can use a reference to the regex instead of cloning it.
This optimzation alone shaves about 50% of execution time.
time ast-grep scan -c eslint/sgconfig.yml TypeScript/src --json > /dev/null
13.89s user, 0.74s system, 274% cpu 5.320 totalThe new flamegraph looks like this.
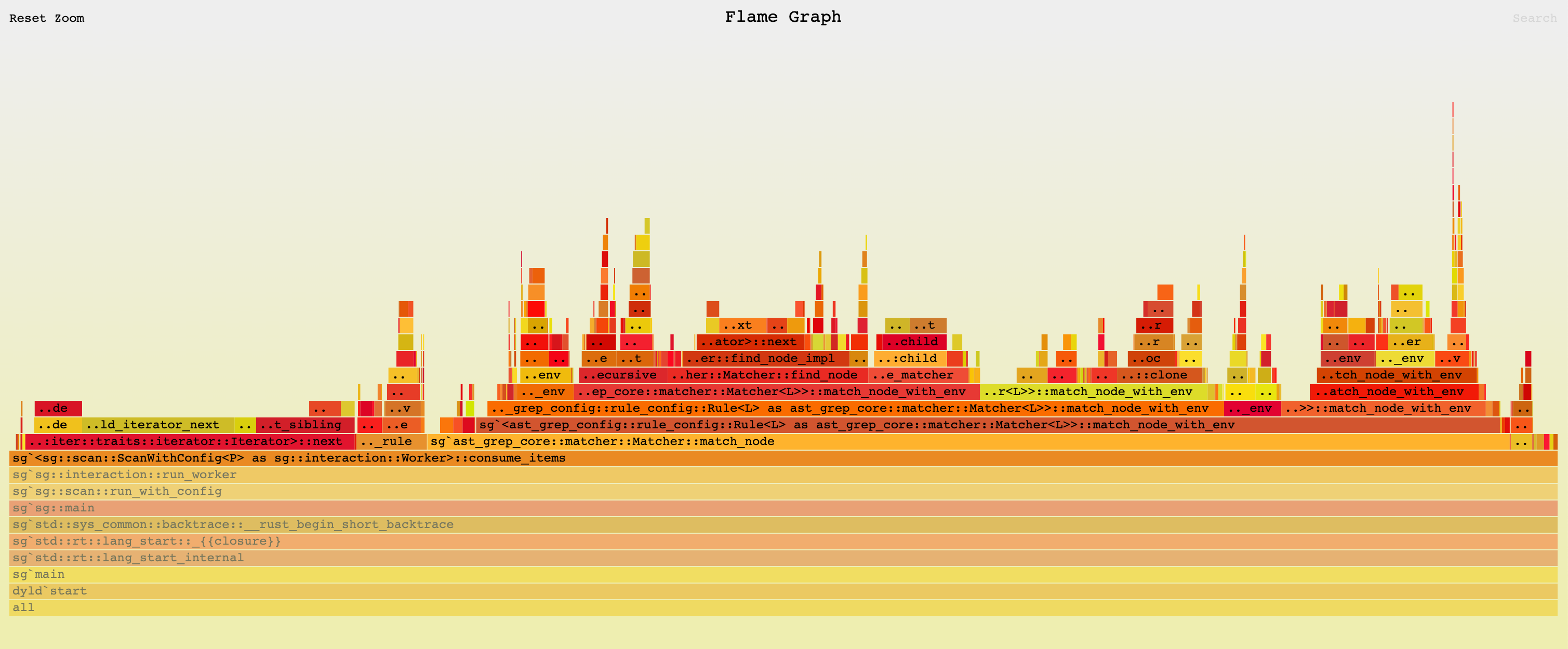
Matching Rule can be Avoided
The second thing I noticed is that the match_node function is called a lot. It is the function that matches a pattern against an AST node. ast-grep can match an AST node by rules, and those rules can be composed together into more complex rules. For example, the rule any: [rule1, rule2] is a composite rule that consists of two sub-rules and the composite rule matches a node when either one of the sub-rules matches the node. This can be expensive since multiple rules must be tried for every node to see if they actually make a match.
I have already forsee it so every rule in ast-grep has an optimization called potential_kinds. AST node in tree-sitter has its own type encoded in a unsigned number called kind. If a rule can only match nodes with specific kinds, then we can avoid calling match_node for nodes if its kind is not in the potential_kinds set. I used a BitSet to encode the set of potential kinds. Naturally the potential_kinds of composite rules can be constructed by merging the potential_kinds of its sub-rules, according to their logic nature. For example, any's potential_kinds is the union of its sub-rules' potential_kinds, and all's potential_kinds is the intersection of its sub-rules' potential_kinds.
Using this optimization, I can avoid calling match_node for nodes that can never match a rule. This optimization shaves another 40% of execution time!
ast-grep scan -c eslint/sgconfig.yml TypeScript/src --json > /dev/null
11.57s user, 0.48s system, 330% cpu, 3.644 totalThe new flamegraph.
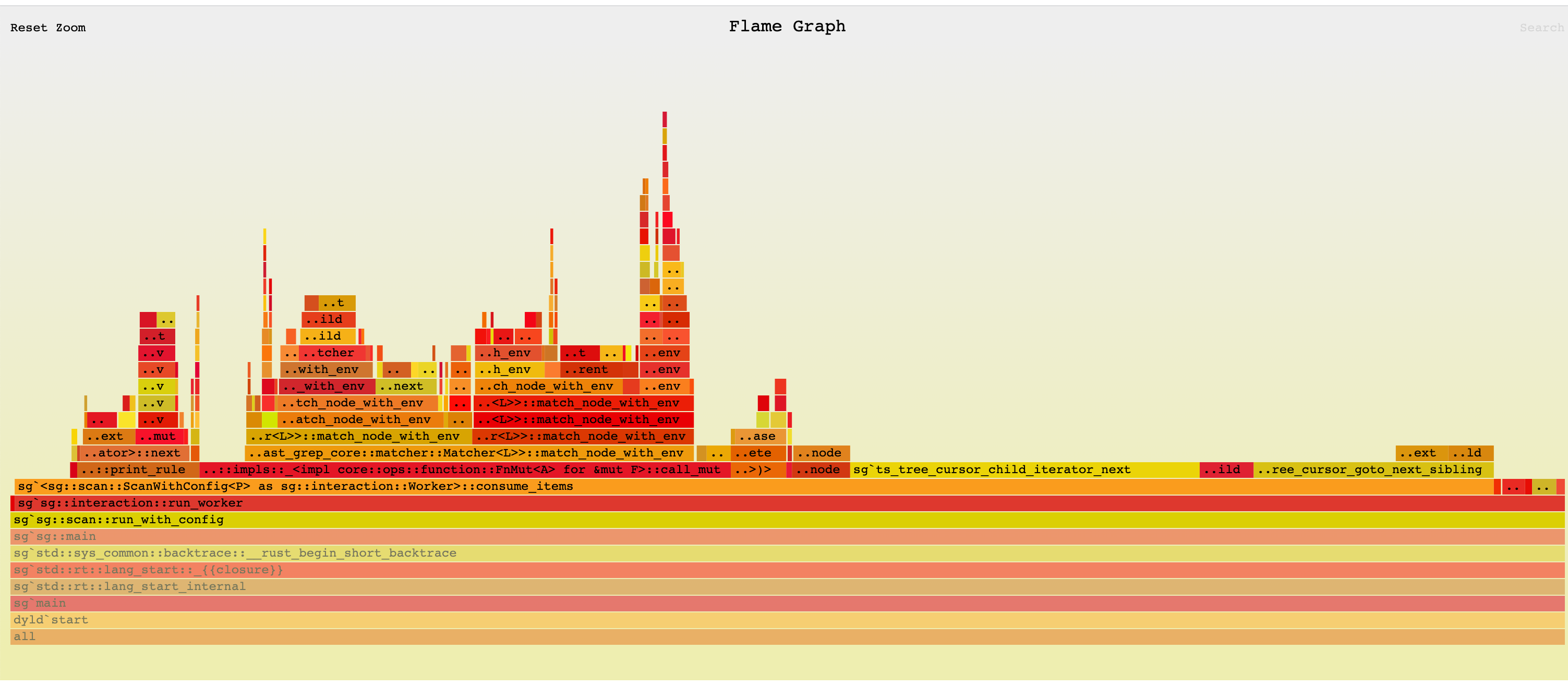
Duplicate Tree Traversal
Finally, the function call ts_tree_cursor_child_iterator_next caught my eyes. It meant that a lot of time was spent on traversing the AST tree.
Well, I dumbly iterating through all the six rules and matching the whole AST tree for each rule. This is a lot of duplicated work!
So I used a data structure to combine these rules, according to their potential_kinds. When I'm traversing the AST tree, I will first retrieve the rules with potential_kinds containing the kind of the current node. Then I will only run these rules against the node. And nodes without any potential_kinds hit will be naturally skipped during the traversal.
This is a huge optimization! The ending result is less than 1 second! And the CPU utilization is pretty good.
ast-grep scan -c eslint/sgconfig.yml TypeScript/src --json > /dev/null
2.82s user, 0.12s system, 301% cpu, 0.975 totalConclusion
The final flamegraph looks like this. I'm too lazy to optimize more. I'm happy with the sub-second result for now.
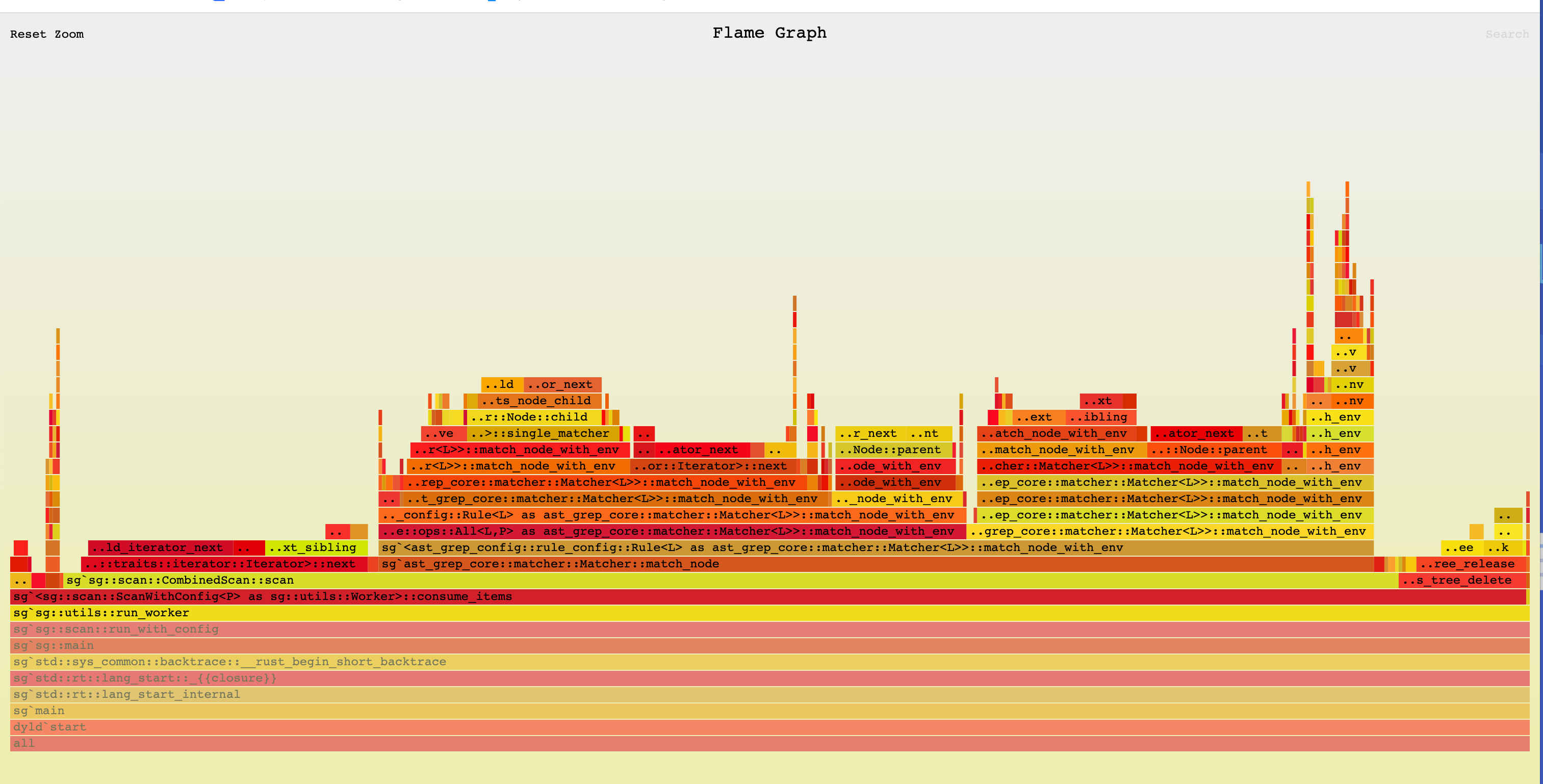
Optimizing ast-grep is a fun journey. I learned a lot about Rust and performance tuning. I hope you enjoyed this post as well.