Rust
This page curates a list of example ast-grep rules to check and to rewrite Rust applications.
Avoid Duplicated Exports
Description
Generally, we don't encourage the use of re-exports.
However, sometimes, to keep the interface exposed by a lib crate tidy, we use re-exports to shorten the path to specific items. When doing so, a pitfall is to export a single item under two different names.
Consider:
pub mod foo;
pub use foo::Foo;The issue with this code, is that Foo is now exposed under two different paths: Foo, foo::Foo.
This unnecessarily increases the surface of your API. It can also cause issues on the client side. For example, it makes the usage of auto-complete in the IDE more involved.
Instead, ensure you export only once with pub.
YAML
id: avoid-duplicate-export
language: rust
rule:
all:
- pattern: pub use $B::$C;
- inside:
kind: source_file
has:
pattern: pub mod $A;
- has:
pattern: $A
stopBy: endExample
pub mod foo;
pub use foo::Foo;
pub use foo::A::B;
pub use aaa::A;
pub use woo::Woo;Contributed by
Julius Lungys(voidpumpkin)
Beware of char offset when iterate over a string Has Fix
Description
It's a common pitfall in Rust that counting character offset is not the same as counting byte offset when iterating through a string. Rust string is represented by utf-8 byte array, which is a variable-length encoding scheme.
chars().enumerate() will yield the character offset, while char_indices() will yield the byte offset.
let yes = "y̆es";
let mut char_indices = yes.char_indices();
assert_eq!(Some((0, 'y')), char_indices.next()); // not (0, 'y̆')
assert_eq!(Some((1, '\u{0306}')), char_indices.next());
// note the 3 here - the last character took up two bytes
assert_eq!(Some((3, 'e')), char_indices.next());
assert_eq!(Some((4, 's')), char_indices.next());Depending on your use case, you may want to use char_indices() instead of chars().enumerate().
Pattern
ast-grep -p '$A.chars().enumerate()' \
-r '$A.char_indices()' \
-l rsExample
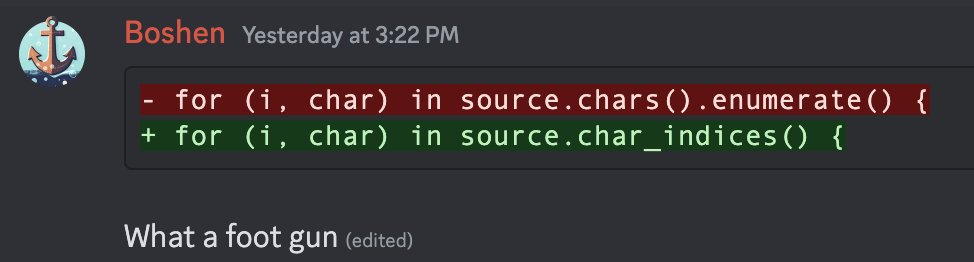
for (i, char) in source.chars().enumerate() {
println!("Boshen is angry :)");
}Diff
for (i, char) in source.chars().enumerate() {
for (i, char) in source.char_indices() {
println!("Boshen is angry :)");
}Contributed by
Inspired by Boshen's Tweet
Get number of digits in a usize Has Fix
Description
Getting the number of digits in a usize number can be useful for various purposes, such as counting the column width of line numbers in a text editor or formatting the output of a number with commas or spaces.
A common but inefficient way of getting the number of digits in a usize number is to use num.to_string().chars().count(). This method converts the number to a string, iterates over its characters, and counts them. However, this method involves allocating a new string, which can be costly in terms of memory and time.
A better alternative is to use checked_ilog10.
num.checked_ilog10().unwrap_or(0) + 1The snippet above computes the integer logarithm base 10 of the number and adds one. This snippet does not allocate any memory and is faster than the string conversion approach. The efficient checked_ilog10 function returns an Option<usize> that is Some(log) if the number is positive and None if the number is zero. The unwrap_or(0) function returns the value inside the option or 0 if the option is None.
Pattern
ast-grep -p '$NUM.to_string().chars().count()' \
-r '$NUM.checked_ilog10().unwrap_or(0) + 1' \
-l rsExample
let width = (lines + num).to_string().chars().count();Diff
let width = (lines + num).to_string().chars().count();
let width = (lines + num).checked_ilog10().unwrap_or(0) + 1; Contributed by
Herrington Darkholme, inspired by dogfooding ast-grep
Unsafe Function Without Unsafe Block
Description
This rule detects functions marked with the unsafe keyword that do not contain any unsafe blocks in their body.
When a function is marked unsafe, it indicates that the function contains operations that the compiler cannot verify as safe. However, if the function body doesn't contain any unsafe blocks, it may be unnecessarily marked as unsafe. This could be a sign that:
- The function should not be marked
unsafeif it doesn't perform any unsafe operations - Or if there are unsafe operations, they should be explicitly wrapped in
unsafeblocks for clarity
This rule helps identify such cases so developers can review whether the unsafe marker is truly necessary or if the code needs to be refactored.
YAML
id: redundant-unsafe-function
language: rust
severity: error
message: Unsafe function without unsafe block inside
note: |
Consider whether this function needs to be marked unsafe
or if unsafe operations should be wrapped in an unsafe block
rule:
all:
- kind: function_item
- has:
kind: function_modifiers
regex: "^unsafe"
- not:
has:
kind: unsafe_block
stopBy: endExample
// Should match - unsafe function without unsafe block (no return type)
unsafe fn redundant_unsafe() {
println!("No unsafe operations here");
}
// Should match - unsafe function with return type, no unsafe block
unsafe fn redundant_with_return() -> i32 {
let x = 5;
x + 10
}
// Should match - unsafe function with complex return type
unsafe fn redundant_complex_return() -> Result<String, std::io::Error> {
Ok(String::from("safe operation"))
}
// Should NOT match - unsafe function with unsafe block
unsafe fn proper_unsafe() -> *const i32 {
unsafe {
let ptr = 0x1234 as *const i32;
ptr
}
}
Contributed by
Inspired by @hd_nvim's Tweet
Rewrite indoc! macro Has Fix
Description
This example, created from a Tweet, shows a refactoring operation being performed on Rust source code. The changes involve removing indoc! macro declarations while preserving the CSS-like content within them.
Previously, the same refactor is implemented by a unreadable monster regex in vim syntax.
Click to see the original regex (neovim, btw)
:%s/\v(indoc!|)(| )([|\{)r#"(([^#]+|\n+)+)"#/`\4`I have to confess that I don't understand this regex even if I use neovim, btw.
Let Claude break it down piece by piece:
:%s/- Vim substitution command for all lines\v- Very magic mode in vim for simpler regex syntax(indoc!|)- First capture group: matches either "indoc!" or nothing(| )- Second capture group: matches either empty string or a space([|\{)- Third capture group: matches either[or{r#"- Matches literalr#"(Rust raw string delimiter)(([^#]+|\n+)+)- Fourth capture group (nested):[^#]+- One or more non-# characters|\n+- OR one or more newlines- Outer
()+makes this repeat one or more times
"#- Matches the closing raw string delimiter- `\4` - Replaces with the fourth capture group wrapped in backticks
This regex is designed to find Rust raw string literals (possibly wrapped in indoc! macro), capture their content, and replace the entire match with just the content wrapped in backticks. It's more precise than my previous explanation and matches the pattern you're showing.
Pattern
ast-grep --pattern 'indoc! { r#"$$$A"# }' --rewrite '`$$$A`' sgtest.rsExample
fn main() {
indoc! {r#"
.foo {
order: 1;
}
"#};
}Diff
fn main() {
indoc! {r#" // [!code --]
`.foo { // [!code ++]
order: 1;
}
"#};
`;
}