Beware of char offset when iterate over a string Has Fix
Description
It's a common pitfall in Rust that counting character offset is not the same as counting byte offset when iterating through a string. Rust string is represented by utf-8 byte array, which is a variable-length encoding scheme.
chars().enumerate() will yield the character offset, while char_indices() will yield the byte offset.
rs
let yes = "y̆es";
let mut char_indices = yes.char_indices();
assert_eq!(Some((0, 'y')), char_indices.next()); // not (0, 'y̆')
assert_eq!(Some((1, '\u{0306}')), char_indices.next());
// note the 3 here - the last character took up two bytes
assert_eq!(Some((3, 'e')), char_indices.next());
assert_eq!(Some((4, 's')), char_indices.next());Depending on your use case, you may want to use char_indices() instead of chars().enumerate().
Pattern
shell
ast-grep -p '$A.chars().enumerate()' \
-r '$A.char_indices()' \
-l rsExample
rs
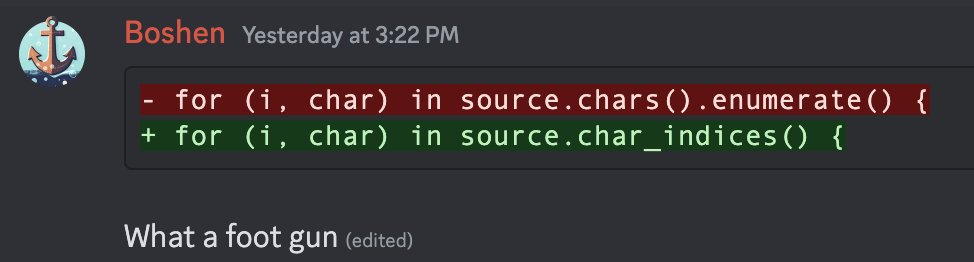
for (i, char) in source.chars().enumerate() {
println!("Boshen is angry :)");
}Diff
rs
for (i, char) in source.chars().enumerate() {
for (i, char) in source.char_indices() {
println!("Boshen is angry :)");
}Contributed by
Inspired by Boshen's Tweet